关于redis的一些原理和开发运维总结。
redis开发运维总结
redis运维日志
安装
1 | $ wget http://download.redis.io/releases/redis-3.2.11.tar.gz |
启动方式
- 直接启动:redis-server
- 动态参数启动:redis-server -p 6380
- 指定配置文件启动:redis-server /path/to/redis-**.conf
推荐基础配置:1
2
3
4
5
6
7
8# 是否以守护进程方式启动
daemonize yes
# redis对外端口
port 6380
# 工作目录
dir ./
# 日志文件
logfile "redis-6380.log"
redis客户端
1 | redis-cli -h ip -p port |
redis API
通用命令
- keys [re pattern]:显示满足通配符匹配的key
- dbsize:查看key总数
- exist key:判断key是否存在
- del key [key…]:删除指定key-value
- expire key seconds:设置key过期时间
- ttl key:查看key剩余过期时间
- persist key:删除key的过期设置
1 | 127.0.0.1:6379> set hello world |
- type key:查看key对应value的数据类型(string hash list set zset)
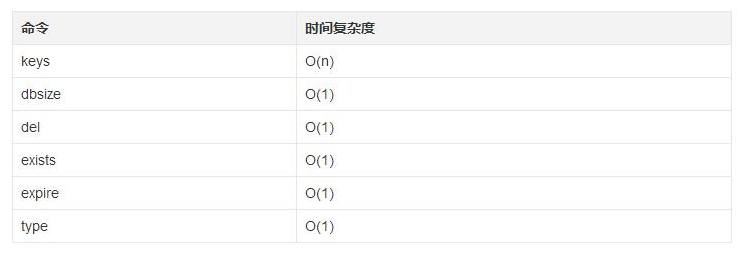
通用命令的时间复杂度
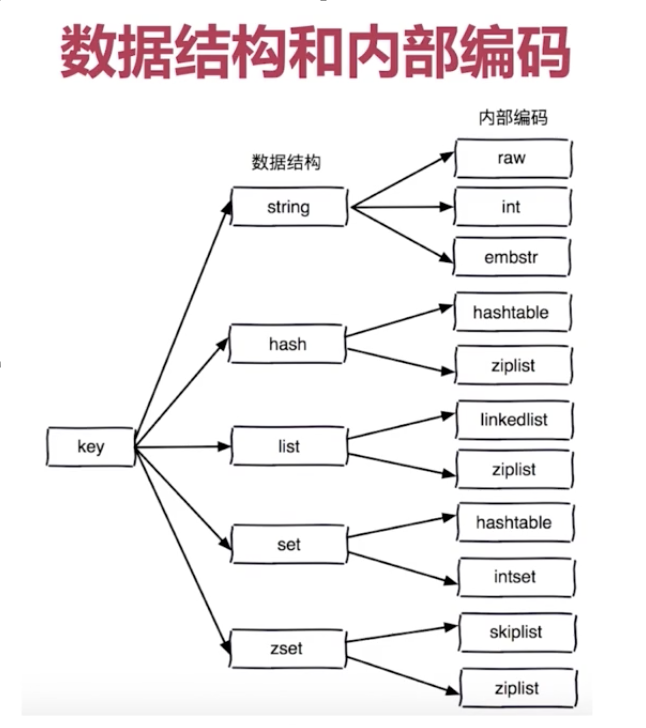
数据结构和内部编码
单线程
redis是单线程设计的,使用时应该注意以下几点:
- 一次只运行一条命令
- 不要执行长(慢)命令
长(慢)命令:keys, flushall, flushdb, slow lua script, mutil/exec, operate big value(collection)都是>=O(n)复杂度的命令
其实redis也不全是单线程,比如异步生成rdb文件等
Redis基本数据类型
字符串
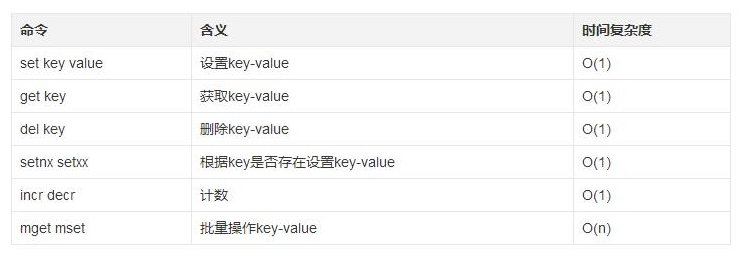
字符串常用命令
时间复杂度
使用场景
- 页面动态缓存
比如生成一个动态页面,首次可以将后台数据生成页面,并且存储到redis 字符串中。再次访问,不再进行数据库请求,直接从redis中读取该页面。特点是:首次访问比较慢,后续访问快速。 - 数据缓存
在前后分离式开发中,有些数据虽然存储在数据库,但是更改特别少。比如有个全国地区表。当前端发起请求后,后台如果每次都从关系型数据库读取,会影响网站整体性能。
我们可以在第一次访问的时候,将所有地区信息存储到redis字符串中,再次请求,直接从数据库中读取地区的json字符串,返回给前端。 - 数据统计
redis整型可以用来记录网站访问量,某个文件的下载量。(自增自减) - 时间内限制请求次数
比如已登录用户请求短信验证码,验证码在5分钟内有效的场景。
当用户首次请求了短信接口,将用户id存储到redis 已经发送短信的字符串中,并且设置过期时间为5分钟。当该用户再次请求短信接口,发现已经存在该用户发送短信记录,则不再发送短信。 - 分布式session
当我们用nginx做负载均衡的时候,如果我们每个从服务器上都各自存储自己的session,那么当切换了服务器后,session信息会由于不共享而会丢失,我们不得不考虑第三应用来存储session。通过我们用关系型数据库或者redis等非关系型数据库。关系型数据库存储和读取性能远远无法跟redis等非关系型数据库。 - Redis字符串常用命令以及应用场景
- 深入解析Redis中常见的应用场景
哈希
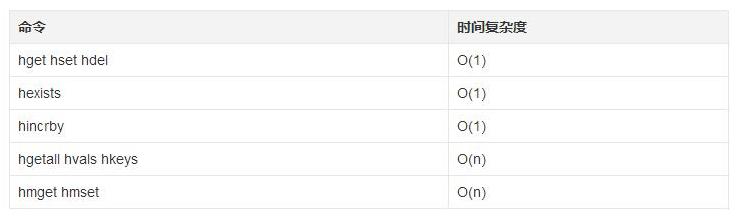
哈希常用命令
时间复杂度
使用场景
满足key-field-value的数据结构类型的,且value变动频繁,例如:
- 购物车
- 缓存视频的基本信息
- 等等
列表
列表常用命令
时间复杂度
使用场景
Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
List 就是链表,相信略有数据结构知识的人都应该能理解其结构。使用List结构,我们可以轻松地实现最新消息排行等功能。List的另一个应用就是消息队列,
可以利用List的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作List中某一段的api,你可以直接查询,删除List中某一段的元素。
- 栈:LPUSH + LPOP
- 队列: LPUSH + RPOP
- 定长集合:LPUSH + LTRIM
- 消息队列:LPUSH + BRPOP
集合
集合常用命令
时间复杂度
使用场景
集合有取交集、并集、差集等操作,因此可以求共同好友、共同兴趣、分类标签等。
1、标签:比如我们博客网站常常使用到的兴趣标签,把一个个有着相同爱好,关注类似内容的用户利用一个标签把他们进行归并。
2、共同好友功能,共同喜好,或者可以引申到二度好友之类的扩展应用。
3、统计网站的独立IP。利用set集合当中元素不唯一性,可以快速实时统计访问网站的独立IP。
有序集合
有序集合常用命令
时间复杂度
使用场景
排行榜系统
有序集合比较典型的使用场景就是排行榜系统,例如视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数。用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
Redis其他功能
慢查询
生命周期
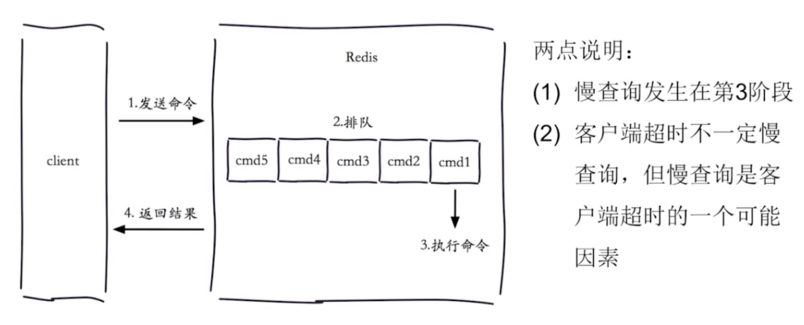
配置和命令
配置
- slowlog-max-len:慢查询队列长度
- slowlog-log-slower-than:慢查询阈值(单位:微秒)
- slowlog-log-slower-than=0, 记录所有命令
- slowlog-log-slower-than<0, 不记录任何命令
配置方法
- 默认值
- config get slowlog-max-len = 128
- config get slowlog-log-slower-than = 10000
- 动态配置
- config set slowlog-max-len 1000
- config set slowlog-log-slower-than 1000
- 默认值
- 命令
- slowlog get [n]:获取慢查询队列
- slowlog len:获取慢查询队列长度
- slowlog reset:清空慢查询队列
- slowlog get [n]:获取慢查询队列
运维经验
- slowlog-max-len不要设置过大,默认10ms,通常设置1ms Redis的QPS是万级的,也就是一条命令平均0.1ms就执行结束了。通常我们翻10倍,设置1ms。
- slowlog-log-slower-than不要设置过小,通常设置1000左右 慢查询队列默认长度128,超过的话,按先进先出,之前的慢查询会丢失。通常我们设置1000。
- 理解命令生命周期 慢查询发生在第三阶段
- 定期持久化慢查询 slowlog get或其他第三方开源工具
pipeline
什么是流水线
未使用流水线的网络通信模型: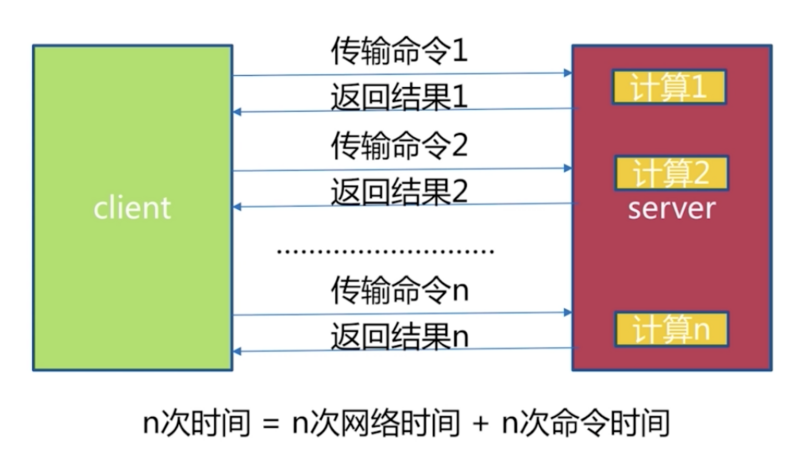
假设客户端在上海,Redis服务器在北京。相距1300公里。假设光纤速度≈光速2/3,即30000公里/秒2/3。那么一次命令的执行时间就是(13002)/(300002/3)=13毫秒。Redis万级QPS,一次命令执行时间只有0.1毫秒,因此网络传输消耗13毫秒是不能接受的。在N次命令操作下,Redis的使用效率就不是很高了。
使用pipeline的网络通信模型: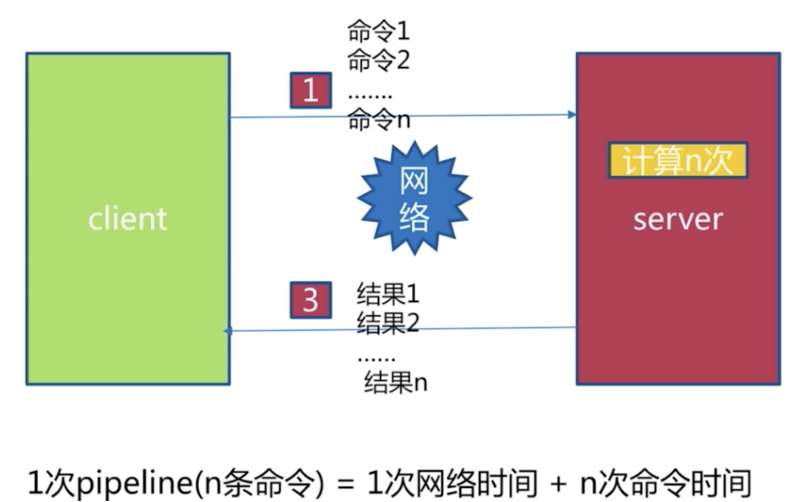
客户端实现
引入maven依赖:
1 | <dependency> |
客户端:
1 | // 不用pipeline |
使用pipelne,10000次hset,总共耗时0.7s,不同网络环境可能有所不同。
可见在执行批量命令时,使用pipeline对Redis的使用效率提升是非常明显的。
与M原生操作对比
mset、mget等操作是原子性操作,一次m操作只返回一次结果。pipeline非原子性操作,只是将N次命令打个包传输,最终命令会被逐条执行,客户端接收N次返回结果。
pipeline使用建议
- 注意每次pipeline携带数据量,pipeline主要就是压缩N次操作的网络时间。但是pipeline的命令条数也不建议过大,避免单次传输数据量过大,客户端等待过长。
- Redis集群中,pipeline每次只作用在一个Reids节点上。
发布订阅
角色
- 发布者(publisher)
- 订阅者(subscriber)
- 频道(channel)
模型
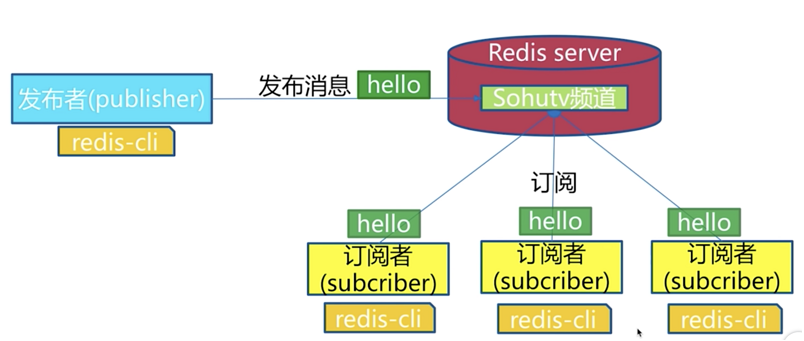
API
发布1
2
3
4
5API:publish channel message
redis> publish sohu:tv "hello world"
(integer) 3 #订阅者个数
redis> publish sohu:auto "taxi"
(integer) #没有订阅者
订阅1
2
3
4
5
6
7
8API:subscribe [channel] #一个或多个
redis> subscribe sohu:tv
1) "subscribe"
2) "sohu:tv"
3) (integer) 1
1) "message"
2) "sohu:tv"
3) "hello world"
取消订阅1
2
3
4
5API:unsubscribe [channel] #一个或多个
redis> unsubscribe sohu:tv
1) "unsubscribe"
2) "sohu:tv"
3) (integer) 0
其他API1
2
3
4psubscribe [pattern…] #订阅指定模式
punsubscribe [pattern…] #退订指定模式
pubsub channels #列出至少有一个订阅者的频道
pubsub numsubs [channel…] #列出给定频道的订阅者数量
- 对比消息队列
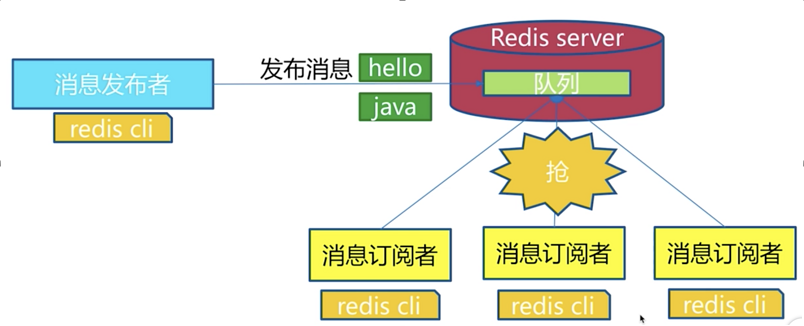
发布订阅模型,订阅者均能收到消息。消息队列,只有一个订阅者能收到消息。因此使用发布订阅还是消息队列,要搞清楚使用场景。
GEO
geo是什么
GEO:存储经纬度,计算两地距离,范围计算等
相关命令
1 | API:geoadd key longitude latitude member # 增加地理位置信息 |
1 | API:geopos key member [member…] # 获取地理位置信息 |
1 | API:geodist key member1 member2 [unit] # 获取两位置距离,unit:m(米)、km(千米)、mi(英里)、ft(尺) |
1 | API: 获取指定位置范围内的地理位置信息集合 |
相关说明
- since redis3.2+
- redis geo是用zset实现的,type geokey = zset
- 没有删除API,可以使用zset的API:zrem key member

